smolcluster
Distributed Deep Learning Library for Heterogeneous Hardware
Train and serve neural networks across Mac minis, Raspberry Pis, MacBooks, and Windows machines - using only Python's socket library. No NCCL, no MPI, no infrastructure assumptions.
smolcluster is an educational project built for learning how distributed training and inference work from the ground up. The codebase is written to be easy to follow, not to be fast or production-ready. It is under heavy development.
Overview
smolcluster is an educational distributed deep learning project built to make it easy to learn how distributed training and inference work from the ground up. It runs across heterogeneous hardware using PyTorch and raw Python sockets. The code is written to be readable and easy to follow - it is not an optimized or production-ready library, and is under heavy active development.
The library supports various distributed training algorithms including Fully Sharded Data Parallelism (FSDP), Classic Data Parallelism (ClassicDP), Elastic Distributed Parallelism (EDP), Model Parallelism, Model Parallelism with Pipeline, and Expert Parallelism. It runs on diverse hardware including Mac minis, Raspberry Pis, MacBooks, and Windows machines.
Training Algorithms
| Algorithm | Best for |
|---|---|
| FSDP (ZeRO Stage 0/1) | Memory-constrained nodes - ZeRO Stage 1 gives ~1/N memory per worker via optimizer state partitioning |
| ClassicDP (All-Reduce) | Balanced clusters - ring all-reduce gradient averaging with configurable bounded staleness |
| EDP (Elastic DP) | Heterogeneous clusters - async with stale gradient tolerance, resilient to stragglers |
| SyncPS (Parameter Server) | Homogeneous clusters - barrier-based synchronization, strict consistency |
| Expert Parallelism | MoE models - distributed expert assignment across nodes |
| Model Parallelism | Large model inference - layer-wise distribution with streaming token generation |
All algorithms support configurable bounded staleness - K=0 for strict sync, K>0 for async up to K steps.
Cluster Architecture
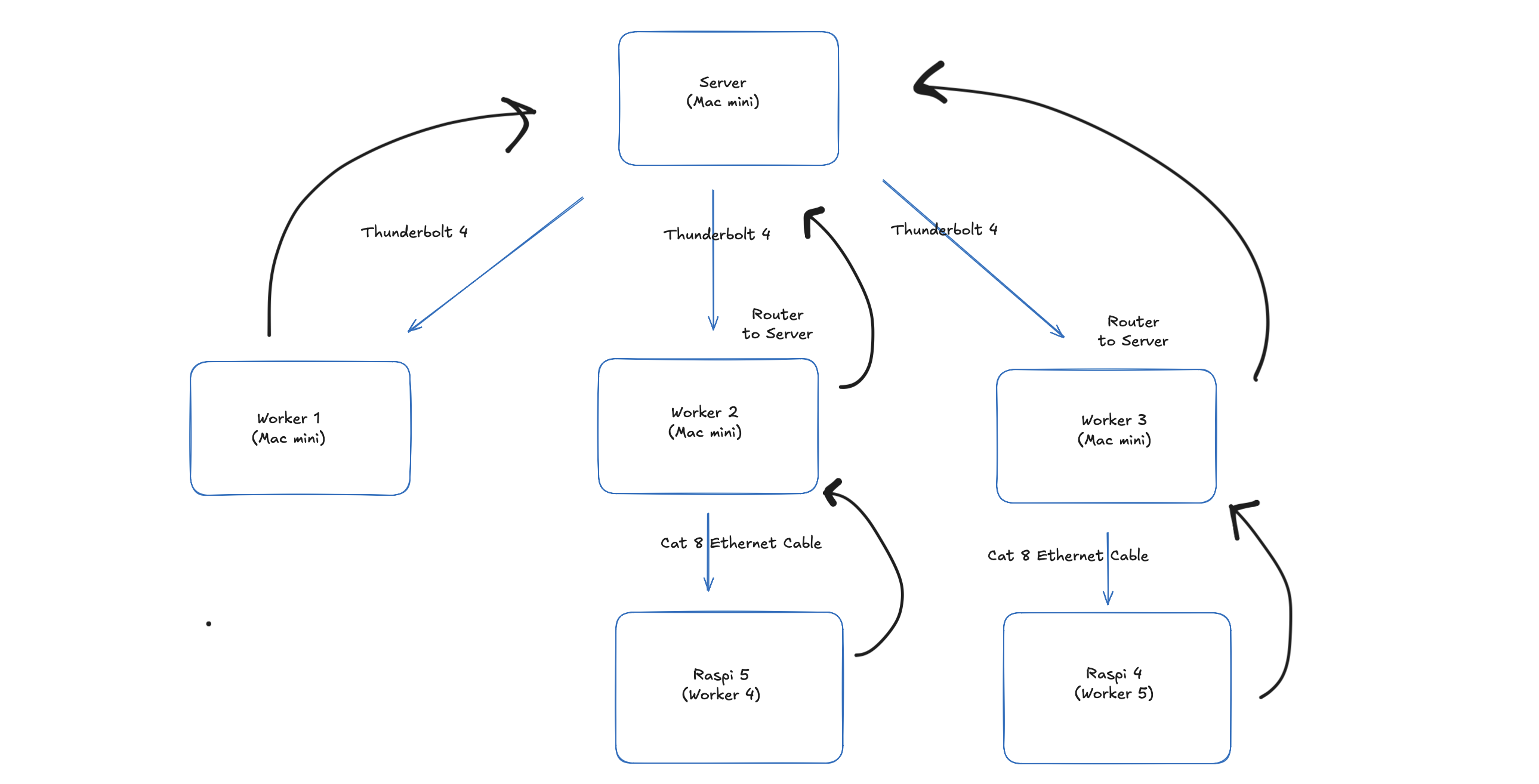
Quick Start
Step-by-step setup guide for Mac Mini (Thunderbolt) and Jetson / home router clusters, with commands ready to copy.
git clone https://github.com/YuvrajSingh-mist/smolcluster.git
cd smolcluster
uv sync
# launch training
bash scripts/launch_edp_train_gpt.sh
# launch inference
bash scripts/inference/launch_mp_inference.sh
bash scripts/inference/launch_api.shKey Features
Distributed Training Algorithms
- Fully Sharded Data Parallelism (FSDP) - ZeRO-optimized data parallelism with configurable optimizer state partitioning. Supports Stage 0 (All-Reduce) and Stage 1 (ZeRO optimizer partitioning) for ~1/N memory reduction. Includes bounded staleness for flexible async training.
- Classic Data Parallelism (ClassicDP) - All-Reduce based data parallelism with bounded staleness control. Workers exchange gradients directly in a fully connected topology with configurable synchronization flexibility.
- Elastic Distributed Parallelism (EDP) - Asynchronous data parallelism with stale gradient tolerance, ideal for heterogeneous clusters.
- Model Parallelism (MP) - Layer-wise model distribution perfect for large models and inference serving.
- Model Parallelism with Pipeline (MPPipeline) - Pipeline-based model parallelism with inter-layer communication and overlapped computation for improved throughput and reduced latency during inference.
- Expert Parallelism (EP) - Sparse mixture-of-experts (MoE) training with distributed expert assignment across nodes. Demonstrates training of sparse models with expert routing across nodes.
Distributed Inference
grove start <script> -n N on the coordinator
and grove join on each worker.
- Supported Inference Algorithms - Pipeline Parallelism and Data Parallelism (DP).
- Streaming Token Generation - Real-time token-by-token generation with activations forwarded sequentially through distributed layers.
- FastAPI Backend - RESTful API server for easy integration with web and mobile clients (iPad, browsers, etc.).
- Multi-Device Support - Serve models across heterogeneous hardware (Mac minis, Raspberry Pis) with automatic activation routing.
- Interactive Chat Interface - React-based web UI and iOS Swift app for real-time interaction with distributed models.
Hardware Support
Train and run inference across heterogeneous hardware including Mac minis, Raspberry Pis, MacBooks, Windows machines, and iPad clients.
Model Support
Built-in support via the Hugging Face Transformers library for Data Parallelism (DP). For Model Parallelism (MP), GPT-2 (117M) is currently supported, with support for additional models coming soon.
Monitoring & Logging
- Weights & Biases Integration - Automatic tracking of training metrics, gradient norms, and hardware utilization.
- Web Interface - React-based chat UI for GPT inference with real-time streaming responses.
Demo
- Model: GPT-2 (117M parameters)
- Hardware: iPad client + 2× Mac Mini M4 (2025)
- Algorithm: Model Parallelism with layer distribution
- Demo: Real-time streaming token generation across distributed layers
- Workflow: User prompts from iPad → activations forwarded between Mac Minis → tokens streamed back
- Model: Llama3.2-1B-Instruct
- Hardware: 3× Mac Minis M4 2025 16GB RAM over LAN
- Algorithm: ClassicDP with all-to-all gradient exchange
- Model: Llama3.2-1B-Instruct
- Hardware: 3× Mac Minis M4 2025 + dedicated parameter server node
- Algorithm: SyncPS with barrier-based synchronization
- Package by Swarnim Jain, integrated into smolcluster
- Auto node discovery over mDNS (Mac) / TCP + Zeroconf (Linux)
- Live per-rank TUI: loss, grad norm, tokens/sec, network I/O
Technical Details
smolcluster implements distributed training and inference across heterogeneous hardware. Each algorithm is written to clearly illustrate how that paradigm works - different cluster configurations, network topologies, and communication patterns - rather than to maximize throughput.
Communication Infrastructure
- Socket-based Communication - Raw TCP sockets for reliable, low-level control over gradient and activation transfers between nodes. No dependency on MPI or specialized networking libraries.
- Pickle Serialization - PyTorch tensors serialized with pickle for straightforward network transmission, with optional gradient quantization for bandwidth reduction.
- Asynchronous I/O - Non-blocking socket operations enable workers to compute while waiting for network transfers in EDP mode.
Distributed Training Modes
- Elastic Distributed Parallelism (EDP) - Workers train independently with stale gradient tolerance. The parameter server accepts gradients from any model version, making it resilient to stragglers and network latency variance. Workers periodically pull the latest weights without synchronization barriers.
- Model Parallelism - Sequential layer distribution across nodes with activation forwarding. Enables training and inference of models exceeding single-device memory. Each worker holds a subset of layers and forwards activations to the next rank.
- Pipeline Model Parallelism - Temporal pipeline parallelism with multiple microbatches in-flight across stages. Reduces bubble size and improves GPU/device utilization during training of large models.
- Expert Parallelism - Distributed training of mixture-of-experts models with expert placement across nodes. Demonstrates sparse model training with expert routing across heterogeneous devices.
Data Management
- Automatic Data Partitioning - Dataset automatically sharded across workers based on global rank and world size, ensuring no data overlap.
- Deterministic Shuffling - Seeded random number generators ensure reproducible data ordering across runs.
- Streaming Support - Streaming data loading for large datasets with PyTorch DataLoader integration.
Fault Tolerance & Monitoring
- Checkpointing - Periodic model snapshots with configurable intervals. Supports resuming training from the latest checkpoint after failures.
- Weights & Biases Integration - Automatic logging of training metrics, gradient norms, per-layer statistics, and system metrics (GPU utilization, memory usage, network throughput).
- Timeout Handling - Configurable timeouts prevent deadlocks when workers fail or network partitions occur.
Performance Optimizations
- Gradient Quantization - Optional 8-bit quantization reduces gradient transfer size by 4× with minimal accuracy impact.
- CPU-based Computation - Designed to utilize CPU cores on commodity hardware (Mac minis, Raspberry Pis) rather than requiring GPUs.
- Mixed Precision Training - FP16 automatic mixed precision support for compatible hardware to accelerate training.
- Gradient Accumulation - Simulates larger batch sizes by accumulating gradients over multiple micro-batches before updating.
Documentation
Comprehensive guides to help you get the most out of smolcluster:
- Cluster Setup - Hardware configuration, network topology, SSH setup
- Network Configuration - Thunderbolt bridges, Ethernet, mDNS discovery
- Training Guide - Algorithm comparison, launch scripts, hyperparameters
- Configuration - YAML config reference for cluster and model settings
- Inference Guide - Model parallelism, FastAPI server, streaming SSE
- Logging Setup - Grafana + Loki distributed log aggregation
License
smolcluster is released under the MIT License.
Contributions are welcome! Visit the GitHub repository to get involved.